In which a twitter race scientist tries to use research to prove something silly.
IQ
metascience
Published
July 14, 2024
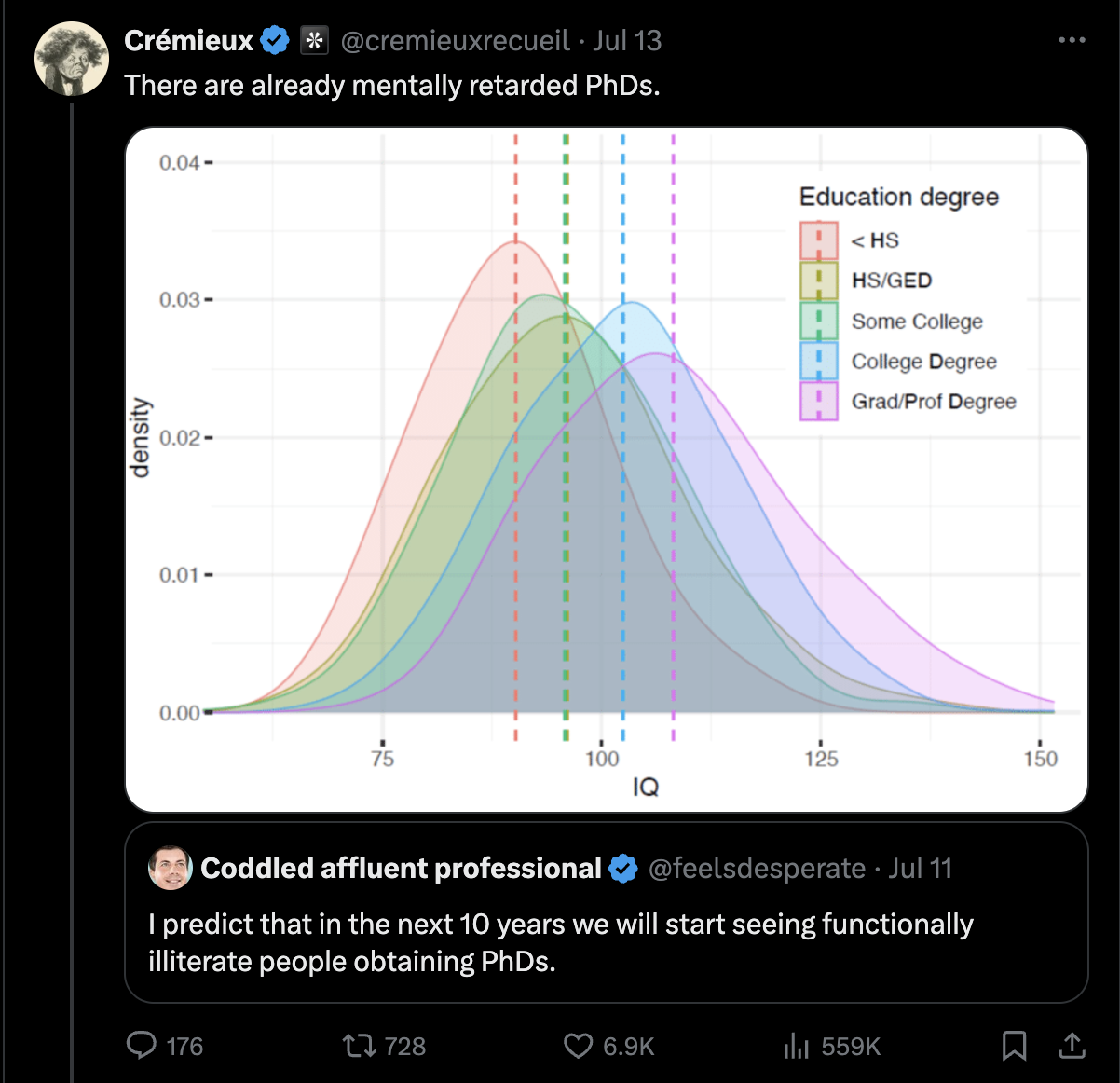
A couple of days ago I saw something silly posted on the internet. The claim was made by someone who people seem to respect on twitter which is already a bad sign, but it was such an extraordinary claim and the plot presented was a Kernel Density Estimation plot so the whole thing reeked of Hákarl.
Status on Twitter only flows to the best people
I even went into the author’s substack post that this plot was used in order to see if there were any additional pieces of evidence that should suggest that there are mentally retarded PhDs out there. But alas I couldn’t find any, just some general information about the decline in IQ among people at higher educational levels due to increased acceptance rates in those programs.
But on the study cited where the data comes from we can look into the definition for higher education they use as well as the distribution of underlying IQs and see if these track with the claim above.
The internal model most people should have for how this works is that there is some effort-IQ matrix that determines a person’s ability to get into a university and to some degree we should not expect low effort low IQ people to be able to achieve post-graduate education. Low IQ low effort people may be able to complete easier programs, and as those programs grow with time their scholarship may decrease. It shouldn’t surprise us to think that there are some changes to the composition of programs, more film studies, art, and journalism Master programs exist nowadays which may have less stringent standards than other more academic disciplines. So to some degree there may be more people enrolled in universities overall but the same or fewer people enrolled in graduate programs. This could explain some degree of change in the IQs of people who have completed these programs over time.
A similar compositional challenge could explain the distribution of IQs of the “Graduate or Professional” study participants, no distinction is made between Master and Ph.D programs in the study cited:
Because of this piece alone one can already cast serious doubt that there are “mentally retarded PhDs”, there may only be mentally retarded Masters degree holders. We can’t know given the data provided!
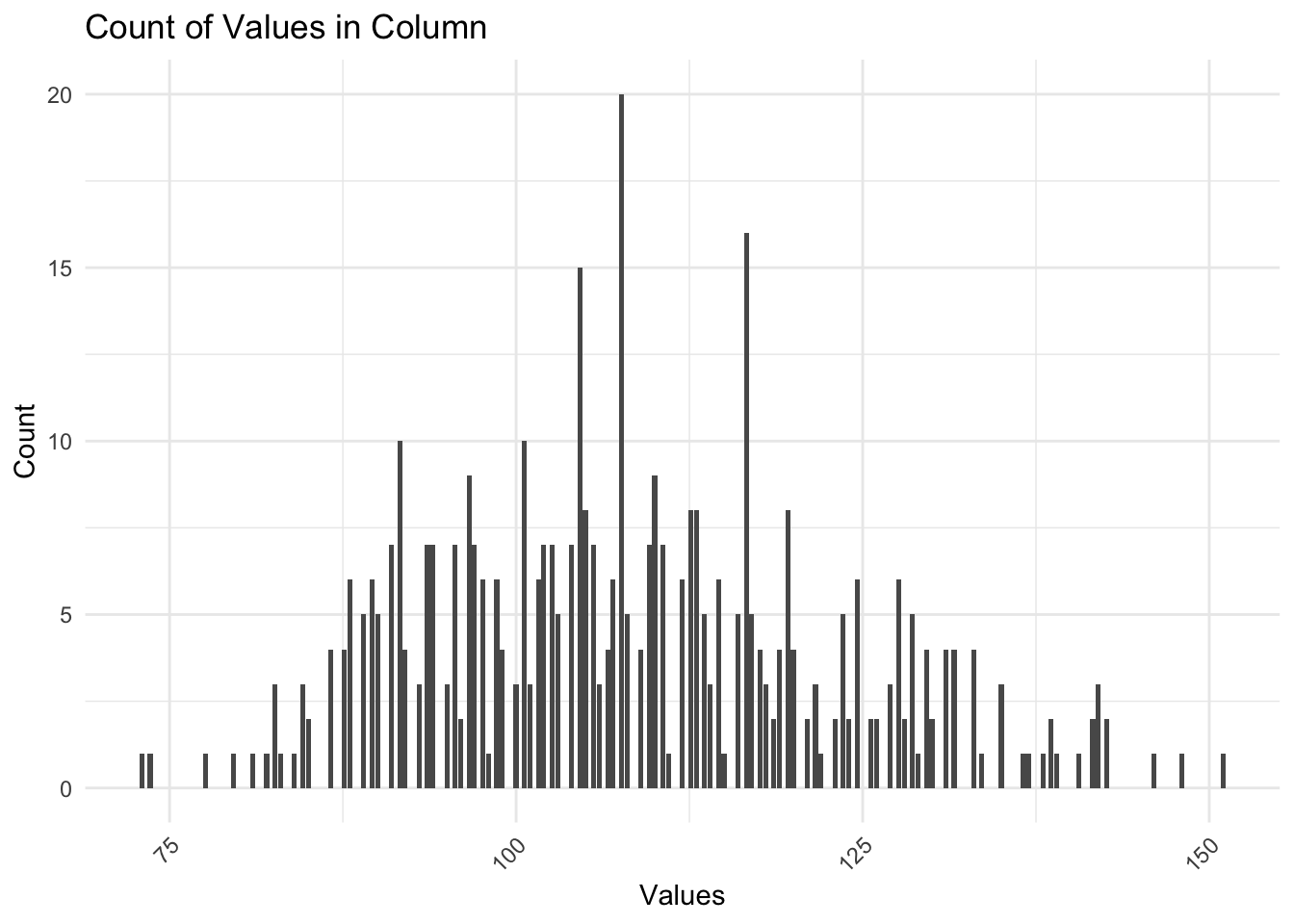
To the data itself we can do some basic observation and some bootstrapping to check if there is room to say that there are mentally retarded Graduate or Professional degree holders. From the raw data provided by the authors for replication we can see that there are no individuals who hold an advanced degree and have an IQ under 70 on either the test or retest.
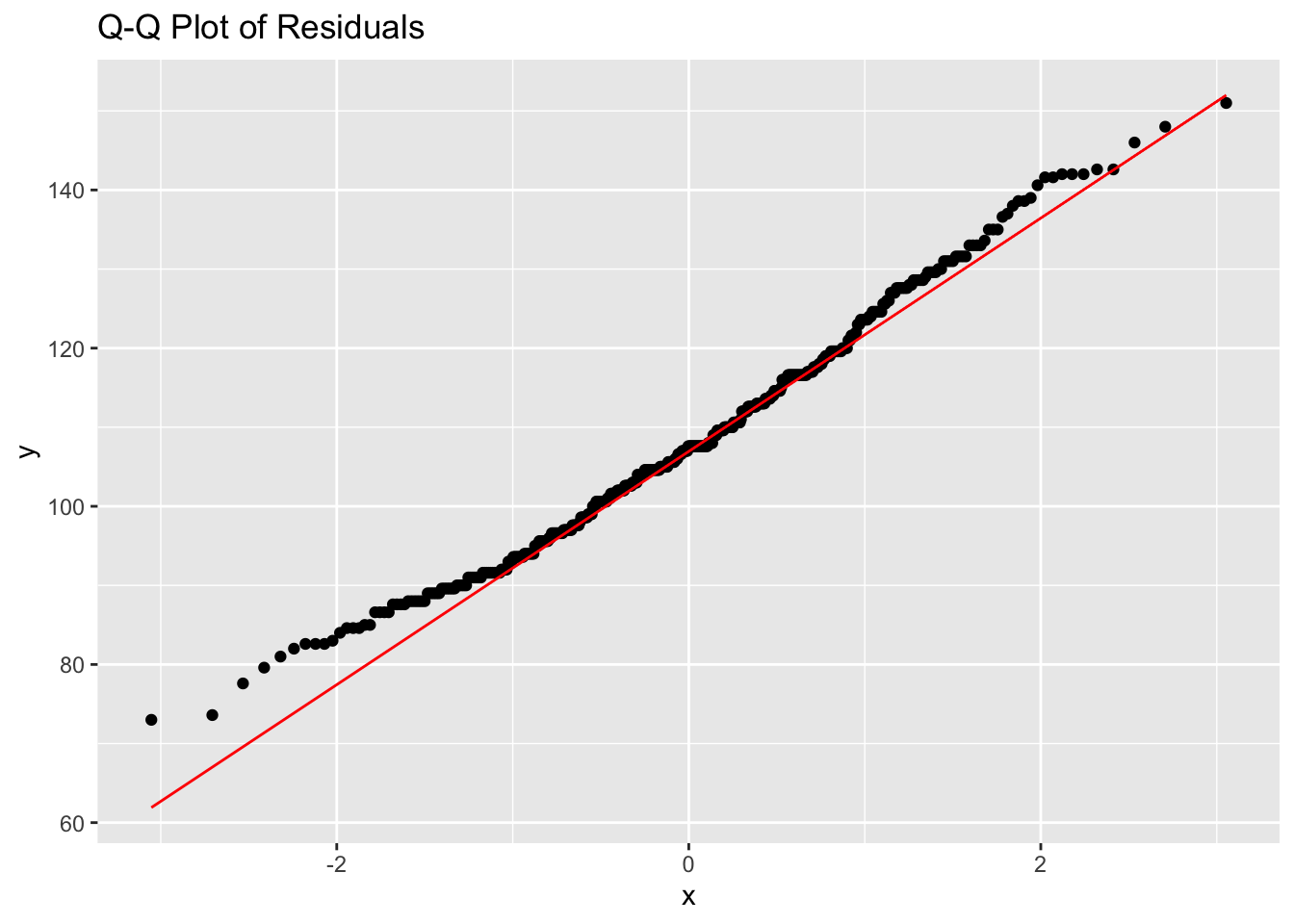
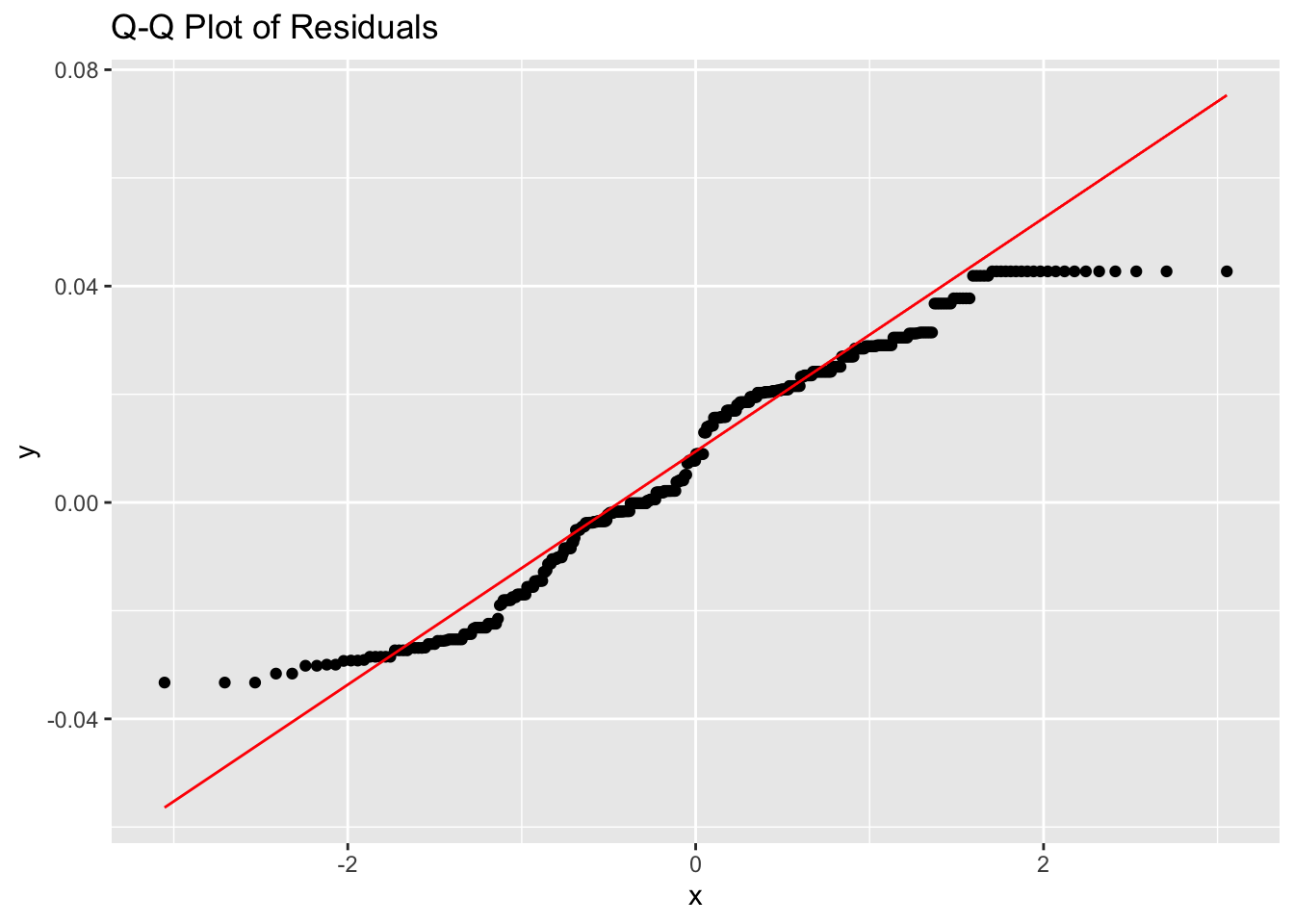
We can check if the full IQ data for the initial test are normally distributed, have excess kurtosis, and plot them against the quantile-quantile norm graph. We find that they are not normally distributed (Shapiro-Wilks test is significant), have light-tails (kurtosis < 3), and the Quantil-Quantile-plot shows us where that light-tailedness is located: the lower end of the IQ distribution!
So it’s nice to see the mental model that most people have of college is still somewhat correct, there is a (leaky) filter that tracks with IQ, if your IQ is lower you’re gonna have a tougher time getting in and your IQ is going to be underrepresented. Remember, this includes Masters programs and PhD programs and the process of getting into a PhD program is more stringent than getting into a Master program in the United States.
Using the bootstrap to check how many people we should expect to be mentally retarded
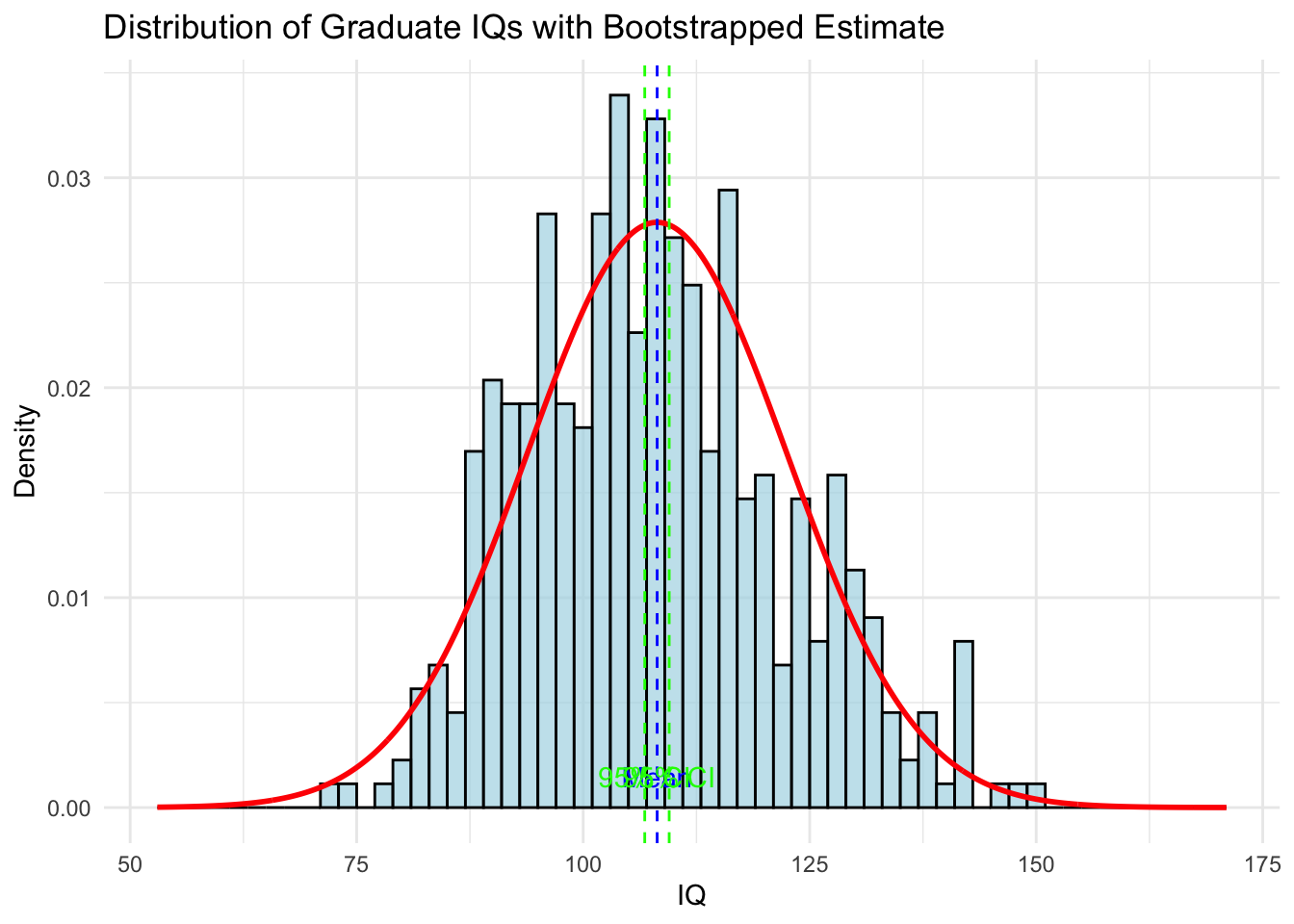
Okay, now we have come to characterize this data a bit, we know that it is non-normal and light tailed. Lets set those two characteristics aside and consider how we might be able to use assumptions of normality to guess there are more mentally retarded people in the graduate degree holding population than there actually are. We use a bootstrap
# Function to compute mean and CI for a samplebootstrap_mean_ci <-function(data, indices) { sample <- data[indices]return(c(mean =mean(sample), sd =sd(sample)))}n_bootstraps <-10000boot_results <-replicate(n_bootstraps, { sample_data <-sample(grad_data$IQ_A, replace =TRUE, size =nrow(grad_data))bootstrap_mean_ci(sample_data, 1:length(sample_data))})boot_df <-as.data.frame(t(boot_results))ci_lower <-quantile(boot_df$mean, 0.025)ci_upper <-quantile(boot_df$mean, 0.975)iq_range <-seq(min(grad_data$IQ_A) -20, max(grad_data$IQ_A) +20, by =0.1)# Calculate the probability density for each IQ valuedensity_values <-sapply(iq_range, function(x) {mean(dnorm(x, mean = boot_df$mean, sd = boot_df$sd))})# Create a data frame for plottingplot_data <-data.frame(IQ = iq_range, Density = density_values)# Create the plotggplot() +geom_histogram(data = grad_data, aes(x = IQ_A, y = ..density..), binwidth =2, fill ="lightblue", color ="black", alpha =0.7) +geom_line(data = plot_data, aes(x = IQ, y = Density), color ="red", linewidth =1) +geom_vline(xintercept =mean(grad_data$IQ_A), color ="blue", linetype ="dashed") +geom_vline(xintercept = ci_lower, color ="green", linetype ="dashed") +geom_vline(xintercept = ci_upper, color ="green", linetype ="dashed") +theme_minimal() +labs(title ="Distribution of Graduate IQs with Bootstrapped Estimate",x ="IQ",y ="Density") +annotate("text", x =mean(grad_data$IQ_A), y =0, label ="Mean", vjust =-1, color ="blue") +annotate("text", x = ci_lower, y =0, label ="95% CI", vjust =-1, color ="green") +annotate("text", x = ci_upper, y =0, label ="95% CI", vjust =-1, color ="green")
Warning: The dot-dot notation (`..density..`) was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(density)` instead.
cat("Probability of IQ < 70:", mean(pnorm(70, mean = boot_df$mean, sd = boot_df$sd)), "\n")
Probability of IQ < 70: 0.003911355
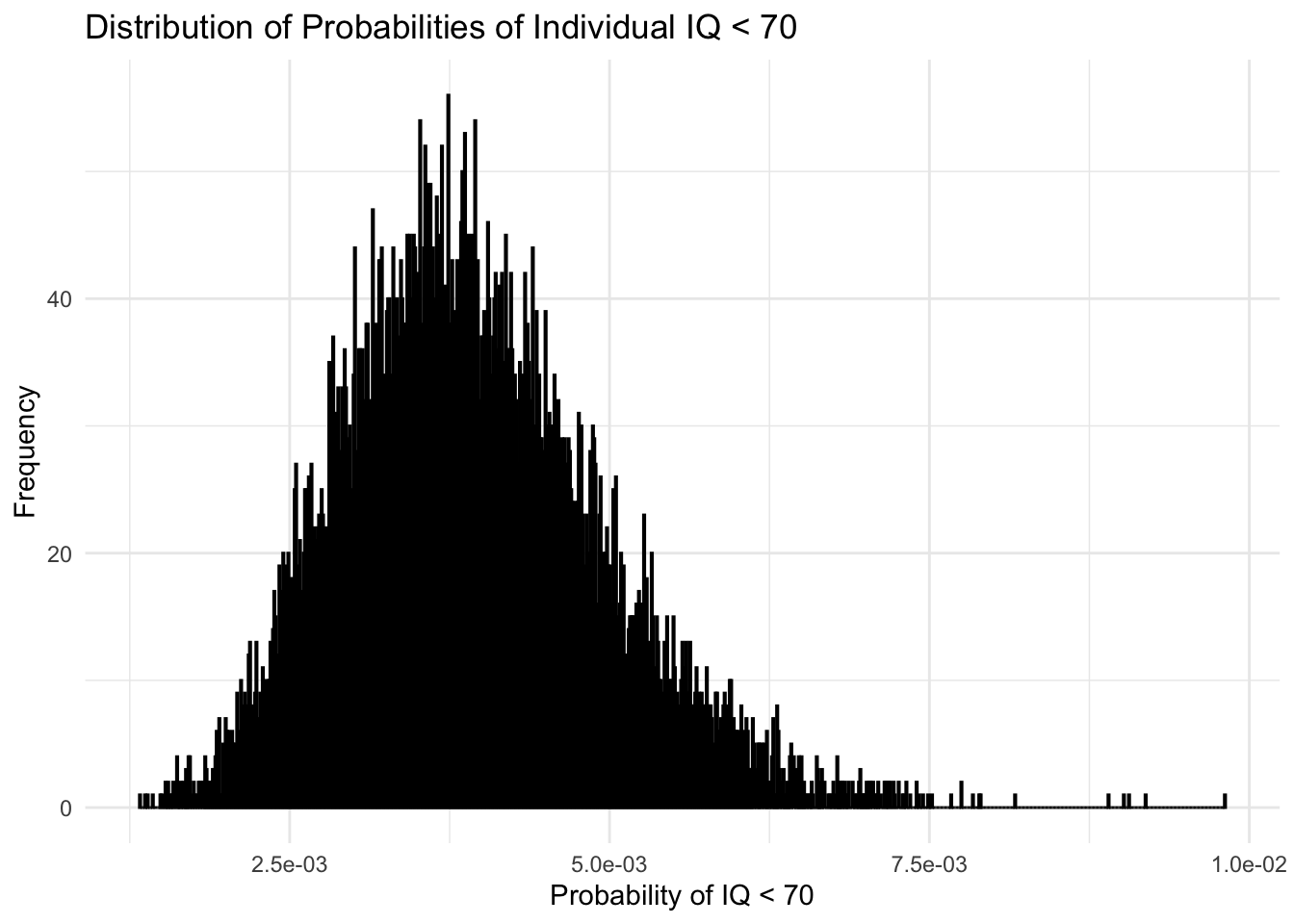
And look! we can see that if we assume some normality that the tails continue out past our data and we can now say that there are indeed individuals with sub-70 IQs in a population that follows the bootstrapped mean and standard deviation. We can even use the below to get the proportion of individuals we expect to have IQ less than 70 using this assumed normality. First we use a function to get the probability of an individual having sub-70 IQ for a given mean and standard deviation and then we calculate the the probabilities for all of our bootstrapped samples. I have plotted the distribution of those probabilities below.
# Function to calculate probability of IQ < 70 for a given mean and sdprob_under_70 <-function(mean, sd) {pnorm(70, mean, sd)}# Calculate probabilities for each bootstrap sampleboot_df$prob_under_70 <-mapply(prob_under_70, boot_df$mean, boot_df$sd)ggplot(boot_df, aes(x = prob_under_70)) +geom_histogram(binwidth =0.00001, fill ="skyblue", color ="black", alpha =0.7) +theme_minimal() +labs(title ="Distribution of Probabilities of Individual IQ < 70",x ="Probability of IQ < 70",y ="Frequency") +scale_x_continuous(labels = scales::scientific)
Finally we can use these probabilities to get a mean probability of a sub-70 IQ being observed as well as confidence intervals. We can finally characterize this in terms of 10000 graduates.
# Calculate average probability and confidence intervalavg_prob <-mean(boot_df$prob_under_70)ci_prob <-quantile(boot_df$prob_under_70, c(0.025, 0.975))cat("Average probability of individual IQ < 70:", avg_prob, "\n")
Average probability of individual IQ < 70: 0.003911355
cat("95% CI for probability of individual IQ < 70:", ci_prob[1], "-", ci_prob[2], "\n")
95% CI for probability of individual IQ < 70: 0.002210871 - 0.006065685
# Expected number of individuals with IQ < 70 in a population of 10,000 graduatesexpected_count <- avg_prob *10000ci_count <- ci_prob *10000cat("Expected number of individuals with IQ < 70 per 10,000 graduates:", expected_count, "\n")
Expected number of individuals with IQ < 70 per 10,000 graduates: 39.11355
cat("95% CI for number of individuals with IQ < 70 per 10,000 graduates:", ci_count[1], "-", ci_count[2], "\n")
95% CI for number of individuals with IQ < 70 per 10,000 graduates: 22.10871 - 60.65685
So for every 10,000 graduate degree holders, we would expect that (under assumptions of normality) we would observe between 22 and 61 mentally retarded degree holders. That seems preposterous. The US military does not accept individuals with sub-80 IQ because they are more trouble than they are worth! Thankfully, this relies on the normality assumptions and we can throw it out but it provides a top-end estimate based on this data.
Other methodological problems - Young people aren’t stable
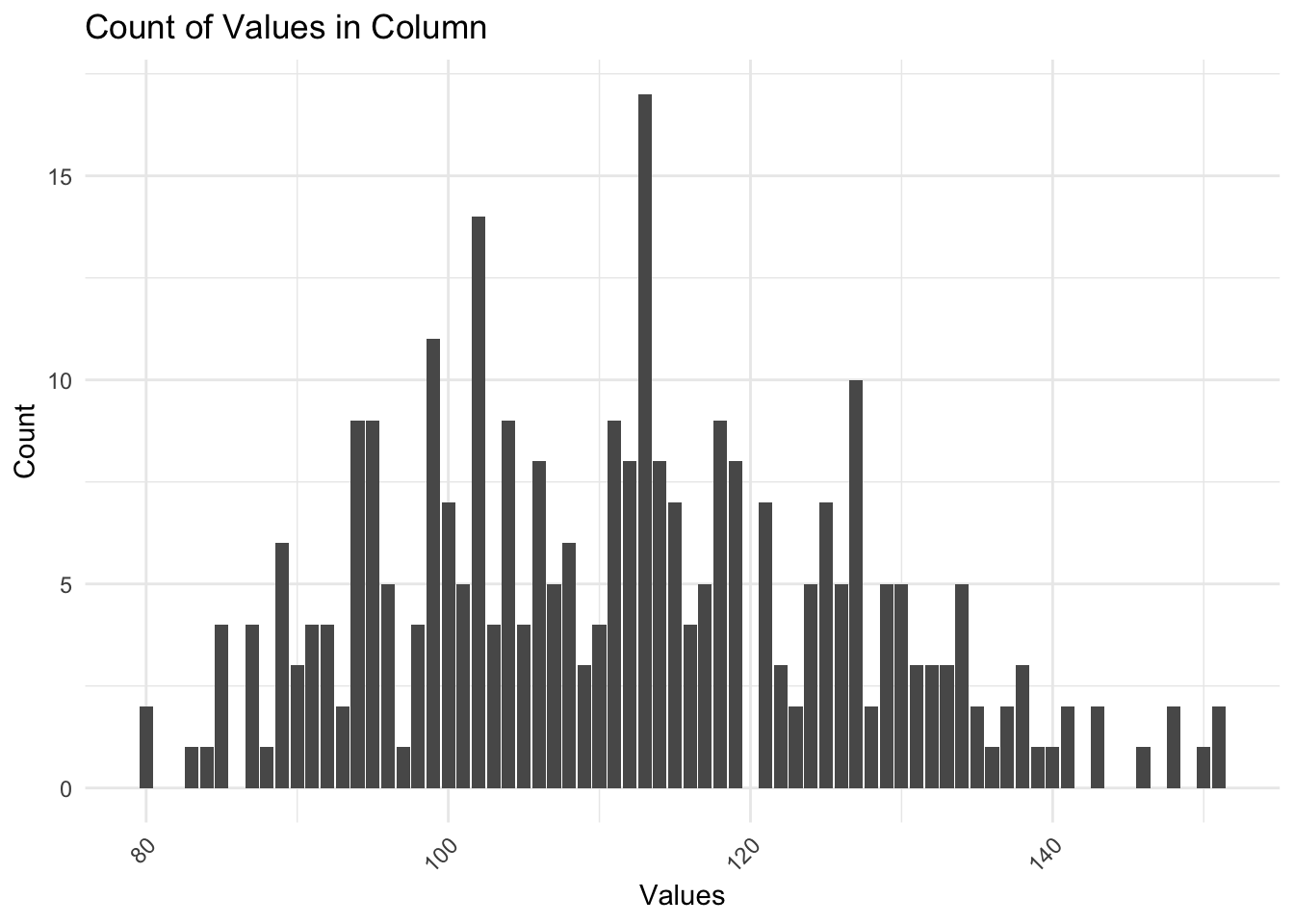
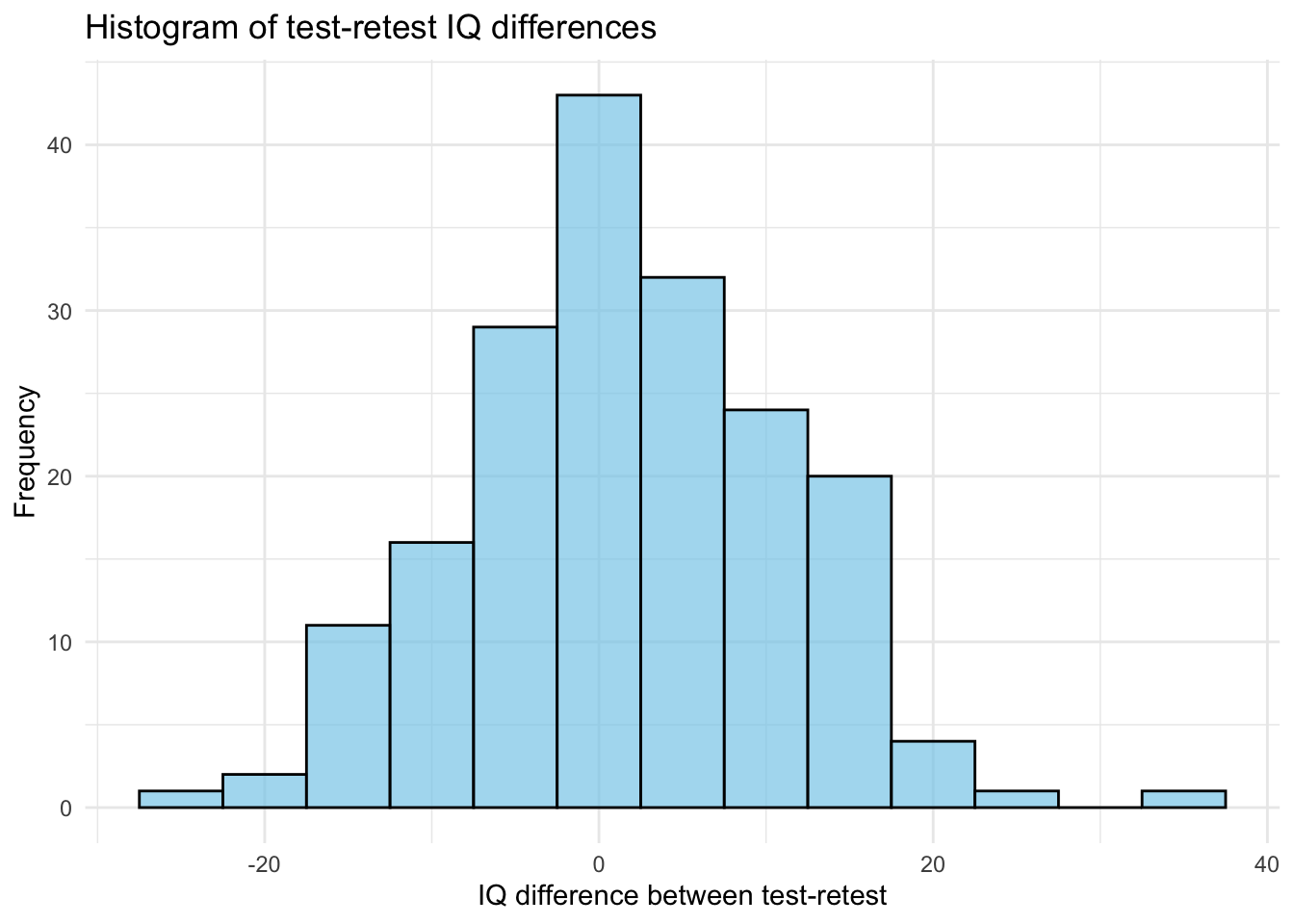
To illustrate the absurdity of our IQ numbers if we take this study as gospel we just have to look at the age at which IQs were measured for the cohorts, age 11 and 17. Among our “slow” sample we can also see that 3 of the 4 come from the COHORT_A = 1 which is the group that was tested at age 11, where IQ’s are not considered stable.
In fact we can see that among the cohort who was tested young and were retested at a later date (according to the paper an average of 6.6 years later) the mean absolute difference between tests was about a half standard deviation (7.64).
Shapiro-Wilk normality test
data: (grad_data_young$iq_diff)
W = 0.99424, p-value = 0.6965
ggplot(grad_data_young, aes(x = iq_diff)) +geom_histogram(binwidth =5, fill ="skyblue", color ="black", alpha =0.7) +labs(title ="Histogram of test-retest IQ differences", x ="IQ difference between test-retest", y ="Frequency") +theme_minimal()
According to a guideline given in Koo and Li (2016) we can rate the agreement of these results as “moderate” which means there was a decent level of movement in the IQs or the tests themselves didn’t capture the underlying IQ properly. But again, this is expected when testing adolescents, hormonal changes even on short time scales can change performance on cognitive tests.
icc_result <-icc(grad_data_young[, c("IQ_A", "IQ_RETEST_A")], model ="twoway", type ="agreement", unit ="single")icc_result
Single Score Intraclass Correlation
Model: twoway
Type : agreement
Subjects = 184
Raters = 2
ICC(A,1) = 0.775
F-Test, H0: r0 = 0 ; H1: r0 > 0
F(183,157) = 8.13 , p = 3.55e-35
95%-Confidence Interval for ICC Population Values:
0.707 < ICC < 0.828
Okay, that aside, our main point besides downgrading our estimation of the IQ scores of children and adolescents being their “true” adult IQ in general the entire measurement regime here is suspect.
Non Normal Distributions
But even if we take it as reflective of the underlying distribution we still cannot assume normality of the IQs of graduate and professional degree holders, so maybe we should try to use the logistic distribution as below and see how our data fits. The logistic distribution is platykurtic so we should hopefully get a decent fit.
fit_logis <-fitdist(grad_data$IQ_A, "logis")# Goodness-of-fit statisticsgof_stat_logis <-gofstat(fit_logis)cat("Logistic distribution AIC:", gof_stat_logis$aic, "\n")
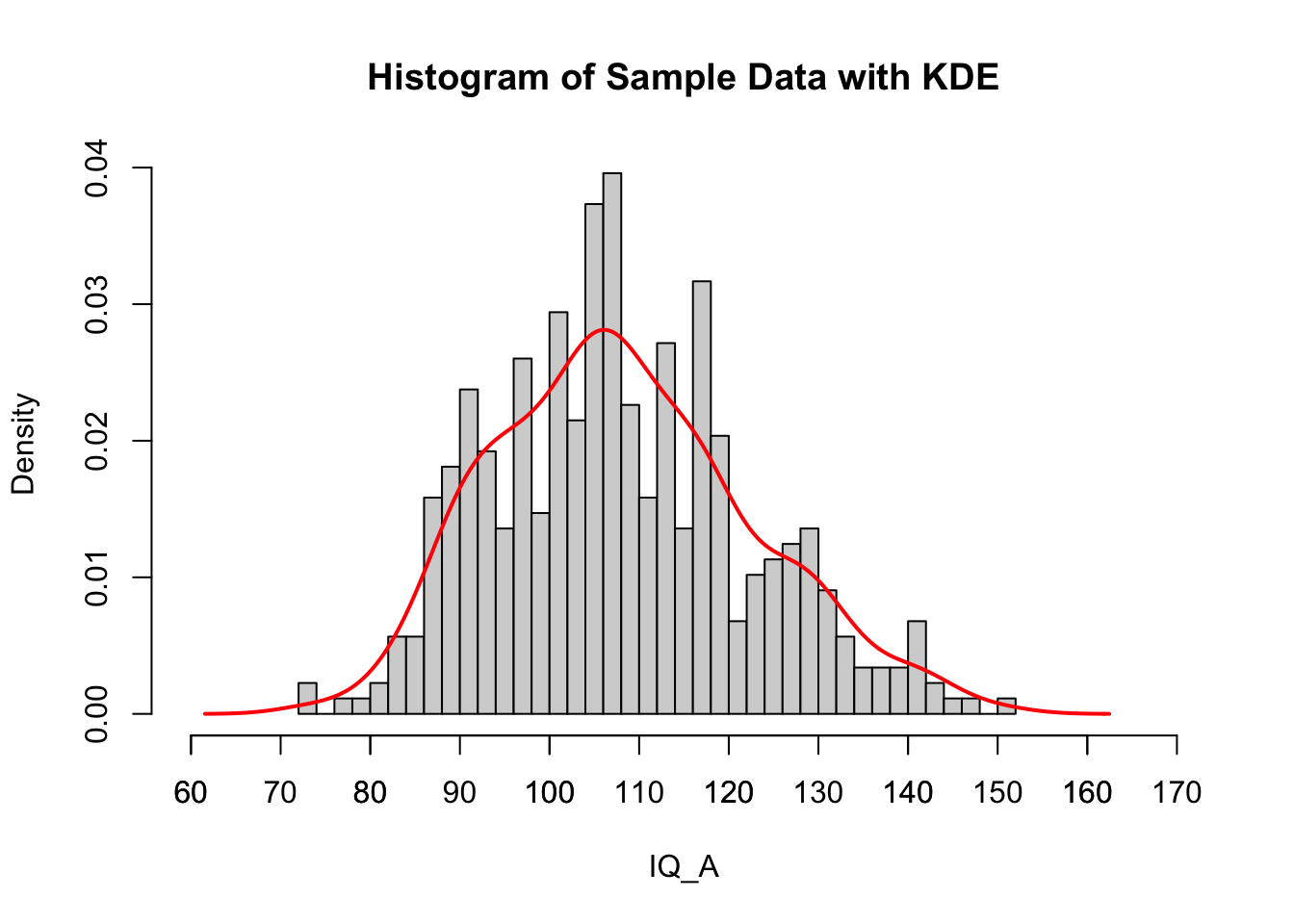
Not great, so I guess we’ll throw out that fit. How about just using the KDE like our authors did?
kde <-density(grad_data$IQ_A)min_x <-floor(min(kde$x) /10) *10max_x <-ceiling(max(kde$x) /10) *10# Visual inspectionhist(grad_data$IQ_A, breaks=30, probability=TRUE, main="Histogram of Sample Data with KDE", xlab="IQ_A", xlim=c(min_x, max_x))lines(kde$x, kde$y, col="red", lwd=2)# Customize x-axis labelsaxis(1, at=seq(min_x, max_x, by=10))
Okay that looks basically about right compared to the original plot.
kde <-density(grad_data$IQ_A, n =2048)kde_function <-approxfun(kde$x, kde$y, rule =2)# Calculate the area under the curve for x < 70area_low_iq <-integrate(kde_function, lower =20, upper =70)$valuecat("Area under the KDE curve for x < 70:", area_low_iq, "\n")
Area under the KDE curve for x < 70: 0.00113071
low_iq_students <- area_low_iq*10000cat("number of students per 10000 with x < 70:", low_iq_students, "\n")
number of students per 10000 with x < 70: 11.3071
Even this, I admit is high for me, I don’t think that this is true and it is only a result of the specification of the estimator function in the KDE and also the smoothness at which it approaches 0 which we can see below:
kde <-density(grad_data$IQ_A, kernel ="triangular", n =2048)kde_function <-approxfun(kde$x, kde$y, rule =2)# Calculate the area under the curve for x < 70area_low_iq <-integrate(kde_function, lower =20, upper =70)$valuecat("Area under the KDE curve for x < 70:", area_low_iq, "\n")
Area under the KDE curve for x < 70: 0.0009890575
low_iq_students <- area_low_iq*10000cat("number of students per 10000 with x < 70:", low_iq_students, "\n")
number of students per 10000 with x < 70: 9.890575
This doesn’t strike me as a very principled view of how we can go from sample to population with respect to our extreme values in general and it doesn’t seem to make much sense to me to assume that there is a value below the minimum we can assume is there despite the data not demonstrating this, the underlying methods of the paper not measuring adult IQ, and life outcomes for adults with Graduate and Professional degrees not reflecting this supposed IQ distribution. And that’s without even getting into the weeds on whether individual papers should be considered good evidence for a phenomena or not (they shouldn’t).
But I thought his real name was Walter White Jr.
And another gripe I’ve had with the paper that I’ve mostly held my tongue to in the above parts is that I don’t think that a Flynn effect of 4.4 points in 7 years is reasonable to correct for. I think mostly this reflects the authors trying to get more data into their cutoff point and rather than checking what an average adjustment might be between testing periods they just norm the groups by subtracting the difference in points from the one with a higher mean. If there was some legitimate difference between the groups it was washed away by that treatment and is not well considered. If I use the uncorrected values below it shrinks the number of sub-70 IQ degree holders estimated by the KDE by nearly half.
Author justification
grad_data$IQ_A <-ifelse(grad_data$COHORT_A ==1, grad_data$IQ_A +4.4, grad_data$IQ_A)kde <-density(grad_data$IQ_A, kernel ="triangular", n =2048)kde_function <-approxfun(kde$x, kde$y, rule =2)# Calculate the area under the curve for x < 70area_low_iq <-integrate(kde_function, lower =20, upper =70)$valuecat("Area under the KDE curve for x < 70:", area_low_iq, "\n")
Area under the KDE curve for x < 70: 0.0005543884
low_iq_students <- area_low_iq*10000cat("number of students per 10000 with x < 70:", low_iq_students, "\n")
number of students per 10000 with x < 70: 5.543884
Conclusion
So where does that leave us? Well, extraordinary claims require extraordinary evidence. Based on the methodological issues, statistical artifacts, and hidden subgroups of this study nobody should use it to claim that there are mentally retarded PhDs out there. It doesn’t follow from any of the evidence laid out in the study, it can’t even be done if we take KDE and the data used here as ground truth because we can’t know which individuals received PhDs or not.
In general we should more carefully read the studies which we cite as evidence, be aware that most studies are bad in some way or another and disbelieve extraordinary claims without thoughtful and careful analysis. If someone makes these types of claims often you should probably ensure they are being highly careful or use evidence like this post to downgrade your assessment of confidence in that person going forward.
 Because of this piece alone one can already cast serious doubt that there are “mentally retarded PhDs”, there may only be mentally retarded Masters degree holders. We can’t know given the data provided!
Because of this piece alone one can already cast serious doubt that there are “mentally retarded PhDs”, there may only be mentally retarded Masters degree holders. We can’t know given the data provided!