Betting on a horse race can oftentimes be fraught with difficulties, if you put in your own horse your knowledge about it may be good you’ll likely know how fast it runs, how well it takes corners, or how well the jockey handles it. However if you have a full stable of some horses that haven’t raced before your knowledge about your other horses is limited in some ways, maybe you’ve timed them on some practice runs, maybe you don’t know if they will be nervous in front of a crowd, etc. If you have a race coming up that you wish to win, you have to take stock of your horses and decide which to put into the race. If you find out however that during the pre-race showing of your horse that it has gotten a little long in the teeth you may find yourself struggling to make a decision to keep your candidate horse in the race or not.
Something other people have pointed out that I want to develop a bit further is the idea that when you know your horse has a degraded chance of getting over the finish line you probably want to sub it out for a higher variance horse even if it may have a worse average race time. Okay that’s a big claim and others have described it a bit but I aim to simulate this and even the choice from a pool of horses whom you don’t have a lot of information about. If you’re in charge of deciding which horse to back even if you have little information and must select a horse at random from your stable you’re likely to still get a better outcome for some underlying distribution of the horses’ performances.
So to motivate this we begin by simulating the horse race in the simplest terms:
Code
library(ggplot2)# number of simulationsn_sims <-10000# define horses with different mean and variancehorses <-list(horse1 =list(mean =45, sd =5),horse2 =list(mean =40, sd =12))# function to simulate one racesimulate_race <-function(horses) { results <-sapply(horses, function(horse) {rnorm(1, mean = horse$mean, sd = horse$sd) })return(results)}# simulate many racesrace_results <-replicate(n_sims, simulate_race(horses))# calculate probabilities of winning (getting above 50)win_probs <-apply(race_results, 1, function(horse_results) {mean(horse_results >50)})print(win_probs)
horse1 horse2
0.1587 0.2020
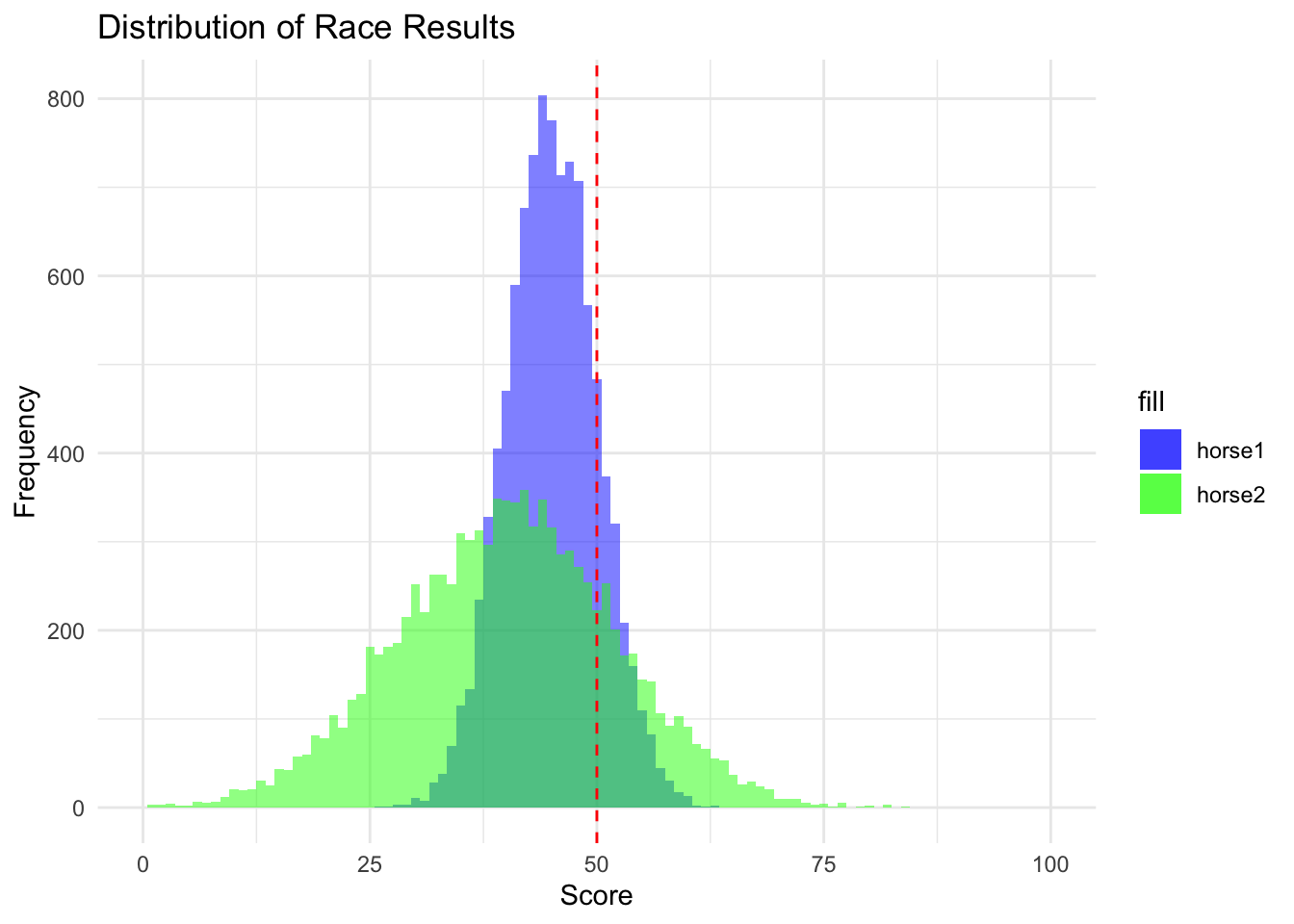
This is the standard sort of argument that people have been making on Twitter and Reddit, that there is a value to having a higher variance candidate even if they have a lower average. The variance more than compensates for the lower average mean as can be seen by the win probabilities and the plot below.
Code
# Convert win_probs to a data framerace_results_df <-data.frame(t(race_results))# Set common limits for x-axiscommon_x_limits <-range(0, 100) # assuming win_probs are probabilities between 0 and 1plot_race_results <-ggplot(race_results_df, aes(x = horse1, fill ="horse1")) +geom_histogram(binwidth =1, alpha =0.5, position ="identity") +geom_histogram(data = race_results_df, aes(x = horse2, fill ="horse2"), binwidth =1, alpha =0.5, position ="identity") +geom_vline(xintercept =50, linetype ="dashed", color ="red") +labs(title ="Distribution of Race Results", x ="Score", y ="Frequency") +xlim(common_x_limits) +scale_fill_manual(values =c("blue", "green")) +# custom fill colorstheme_minimal()plot_race_results
Lets say that we accept that there may be significantly worse and significantly better horses among our pool of candidate horses, some may outright lose and some may outright win a majority of the time. Well we can still use the above analysis to decide whether it makes sense to go with our old nag or randomly select amongst these horses. If we assume that the characteristics of the new horse are selected randomly from a uniform distribution then we actually end out still favoring the random selection than our old nag.
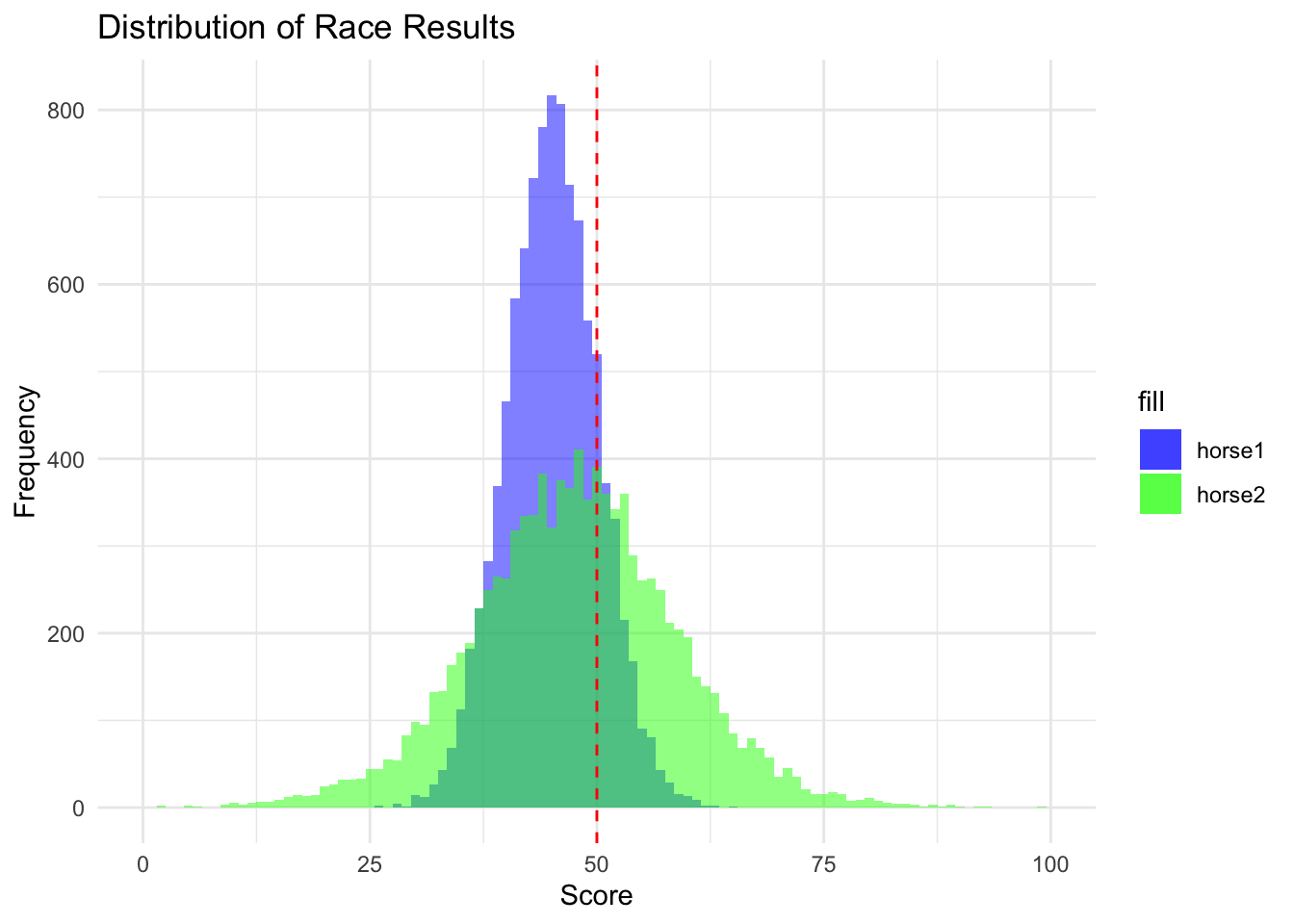
In this case we set the limits of mean vote share to 40 and 55 and the low and high standard deviations to between 5 and 15.
Code
# number of simulationsn_sims <-10000# define horse1 with a fixed mean and variancehorse1 <-list(mean =45, sd =5)# function to generate a random horse with specified mean and variance rangesgenerate_random_horse <-function(mean_range, sd_range) { mean <-runif(1, mean_range[1], mean_range[2]) sd <-runif(1, sd_range[1], sd_range[2])return(list(mean = mean, sd = sd))}# function to simulate one racesimulate_race <-function(horse1, mean_range, sd_range) { horse2 <-generate_random_horse(mean_range, sd_range) horse1_result <-rnorm(1, mean = horse1$mean, sd = horse1$sd) horse2_result <-rnorm(1, mean = horse2$mean, sd = horse2$sd)return(c(horse1_result, horse2_result))}# simulate many racesmean_range <-c(40, 55)sd_range <-c(5, 15)race_results <-replicate(n_sims, simulate_race(horse1, mean_range, sd_range))race_results <-t(race_results) # transpose for easier handling# calculate probabilities of winning (getting above 50)win_probs <-colMeans(race_results >50)names(win_probs) <-c("horse1", "horse2")# print win probabilitiesnames(win_probs) <-c("horse1", "horse2")print(win_probs)
horse1 horse2
0.1628 0.4085
Code
# create a data frame for plottingrace_results_df <-data.frame(horse1 = race_results[, 1],horse2 = race_results[, 2])
Code
plot_race_results <-ggplot(race_results_df, aes(x = horse1, fill ="horse1")) +geom_histogram(binwidth =1, alpha =0.5, position ="identity") +geom_histogram(data = race_results_df, aes(x = horse2, fill ="horse2"), binwidth =1, alpha =0.5, position ="identity") +geom_vline(xintercept =50, linetype ="dashed", color ="red") +labs(title ="Distribution of Race Results", x ="Score", y ="Frequency") +xlim(common_x_limits) +scale_fill_manual(values =c("blue", "green")) +# custom fill colorstheme_minimal()plot_race_results
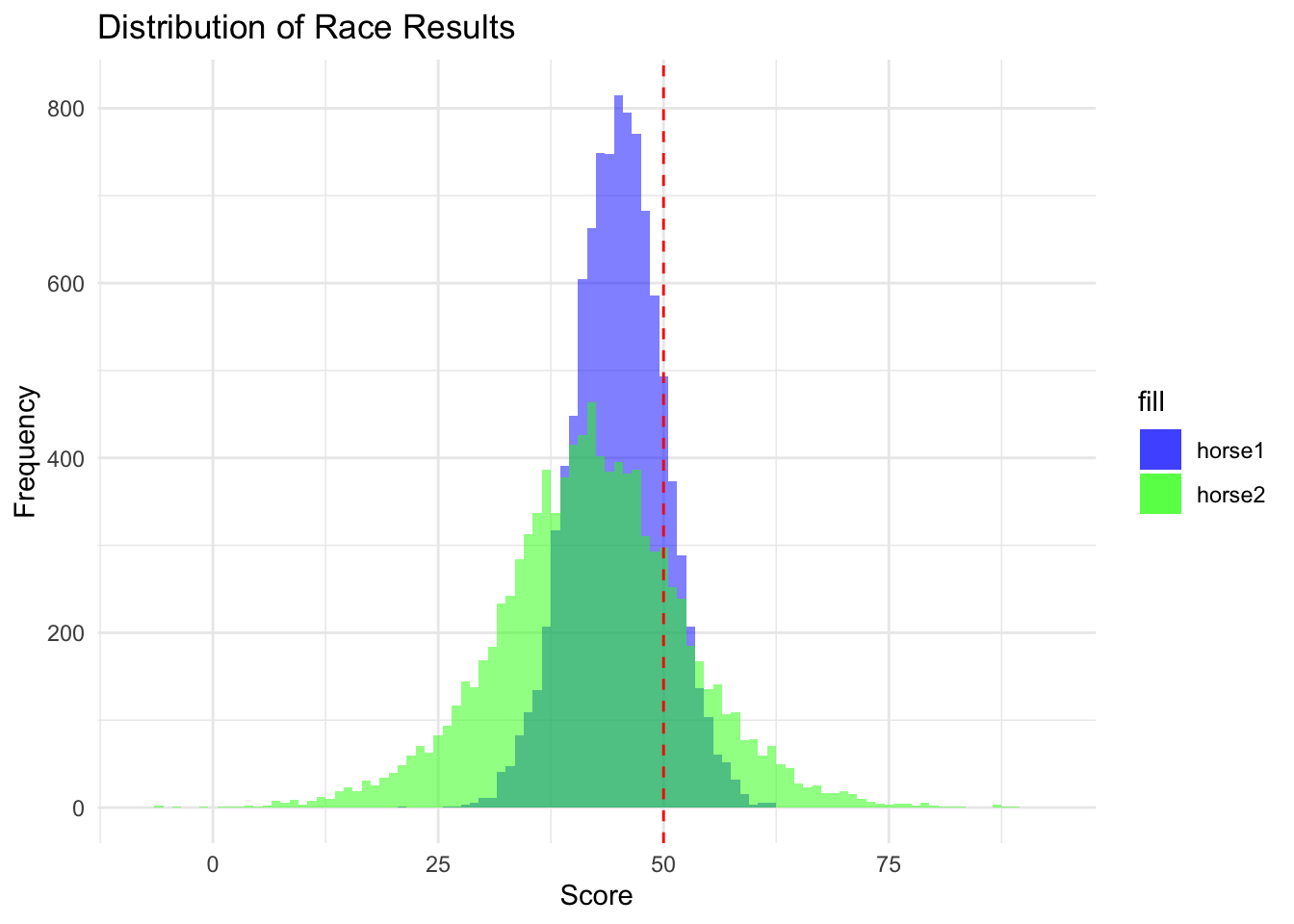
And if the above didn’t convince you or you think the parameterization is too generous to our potential candidate pool then we can change our assumptions about the potential candidate pool to be more dour. Whether that is because an interlocutor might believe that the selection of candidates via the DNC is worse due to primary voters being weird (see: Mitt Romney changing his long held positions to appeal to Republican primary voters in 2012) or because the Democrats will suffer from low fundraising or low energy. As we can see even if we assume that our candidates are strictly worse in terms of mean vote share than our current candidate (by lowering their maximum mean vote shares to that of the original candidate) the higher variability of the choice in candidates and possible outcomes leads us to still prefer to select a new candidate.
Here we plot the race results, note the win condition is the vertical line at 50. It is plain to see that the amount of probability mass even when we select a random candidate from a pool with candidates that would have mean vote share lower than our original candidate it is still prudent to choose a new candidate. This is assuming of course that we select from a pool of candidates where their national vote share would be as low as 40% which is much lower than any presidential election in recent history.
Code
common_x_limits <-range(c(race_results_df$horse1, race_results_df$horse2))common_y_limits <-range(0, # assuming y-axis starts from 0max(hist(race_results_df$horse1, plot =FALSE)$counts,hist(race_results_df$horse2, plot =FALSE)$counts ))plot_race_results <-ggplot(race_results_df, aes(x = horse1, fill ="horse1")) +geom_histogram(binwidth =1, alpha =0.5, position ="identity") +geom_histogram(data = race_results_df, aes(x = horse2, fill ="horse2"), binwidth =1, alpha =0.5, position ="identity") +geom_vline(xintercept =50, linetype ="dashed", color ="red") +labs(title ="Distribution of Race Results", x ="Score", y ="Frequency") +xlim(common_x_limits) +scale_fill_manual(values =c("blue", "green")) +# custom fill colorstheme_minimal()plot_race_results
Sorry I think I may have gotten a bit confused about what topic we were discussing, but the point stands. Even if you have a relatively unknown set of horses, the high variability play is the one to choose if you know that your original horse is one that is lagging behind in its performance with some decent level of confidence. The current betting market odds, polling, and forecasting all indicate that those with money on the line believe it is paramount that a new stallion is found.